OpenAI released GPT-5.4 on March 5 and it set new records across every major benchmark. But a month later, the conversation has moved past the scores. The real story is what this generation of AI is becoming — and it’s not a chatbot anymore.
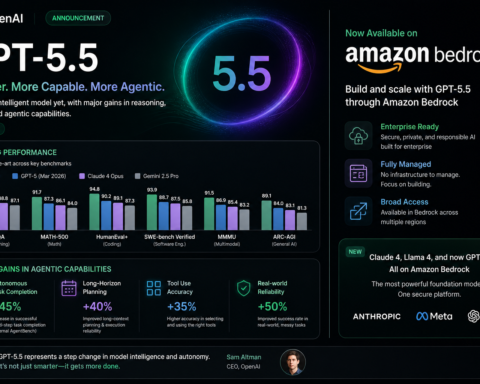
When OpenAI released GPT-5.4 on March 5, 2026, the press coverage focused on the benchmarks. And the benchmarks were genuinely impressive — GPT-5.4 scored 83% on GDPval, the evaluation that tests AI performance across real knowledge work tasks spanning 44 occupations. That number means AI matched or exceeded human professional performance on 83 out of 100 comparable tasks. For context, its predecessor GPT-5.2 scored 70.9%. That’s not a marginal gain.
But six weeks later, sitting with what this model actually is and what OpenAI has done around it, the benchmark score feels like the least interesting part.
Let me explain what I mean.
What Changed That Actually Matters
The model can now think in the open. One of the quieter but more practically significant additions in GPT-5.4 Thinking is that it now shows you an upfront plan while it’s working. You submit a complex task, and instead of waiting for the final output to discover it went in the wrong direction, you can watch the model reason through its approach and correct it mid-response. That sounds small. In practice, for anyone who’s spent time arguing with a long AI output that misunderstood the brief somewhere in the middle — it changes the workflow significantly.
Computer use is now native, not bolted on. GPT-5.4 is the first mainline model to incorporate what OpenAI calls native computer-use capabilities, enabling agents to operate computers and carry out complex workflows across applications. The OSWorld-Verified benchmark scores confirm this: GPT-5.4 hit 75% — the first AI to surpass the human baseline of 72.4% on desktop task automation. When a model can look at a screen, understand what it sees, and take actions with a cursor, the category of task it can handle expands well beyond text generation.
The coding story is a merger. GPT-5.4 incorporates the capabilities of GPT-5.3-Codex, OpenAI’s dedicated coding agent, into the mainline model. The implication is that the same model you use for writing, research, and analysis is also the model doing autonomous code generation, test running, and bug fixing. That unification matters for workflows — you stop routing different tasks to different specialized models.
Hallucinations dropped significantly. OpenAI claims GPT-5.4 is 33% less likely to make errors in individual claims compared to GPT-5.2, and overall responses are 18% less likely to contain errors. These are self-reported numbers so treat them with appropriate skepticism — but the directional improvement is consistent with what independent testers have observed.
The Codex Situation Is Actually Wild
Separate from the model itself, what OpenAI is building around Codex is worth paying attention to.
The desktop app now features what OpenAI calls “background computer use” — Codex can use all the apps on your Mac by seeing, clicking, and typing with its own cursor. Multiple agents can work in parallel without interfering with what you’re doing in other windows. There’s an in-app browser where you can comment directly on pages to give precise instructions to the agent. And Codex can now generate and iterate on images using the same workflow.
This is a coding agent that is increasingly indistinguishable from a digital employee. You can hand it a task, walk away, and return to find it executed — tests run, bugs fixed, commits ready for review.
The 46% “most loved” developer tool rating in the LangChain survey from early 2026 reflects this. Developers who have integrated Claude Code or OpenAI Codex into their workflows aren’t describing them as “really good autocomplete.” They’re describing them as members of the team.
The New Pricing Tier Everyone Should Know About
Buried in the April release notes is something practical that affects regular users: OpenAI introduced a $100/month Pro tier between Plus ($20/month) and Pro ($200/month). The $100 tier is “built for longer, high-intensity Codex sessions” — which in practice means heavy coding users who were hitting limits on Plus but didn’t need the full $200/month ceiling now have a middle option.
For enterprise users, the average ChatGPT Enterprise user is reportedly saving 40-60 minutes per day. Heavy users say more than 10 hours per week. At $200/month, the ROI calculation for professional use is becoming straightforward in a way it wasn’t even six months ago.
One other useful update from the release notes: ChatGPT now auto-converts pastes of more than 5,000 characters into attachments rather than inline text. This is the kind of UX detail that sounds trivial but actually prevents a common frustration — having a massive paste eat your entire context window before the model processes it.
GPT-Rosalind: The Announcement That Didn’t Get Enough Attention
Somewhere in the noise of the GPT-5.4 launch, OpenAI announced something that deserves more coverage than it got: GPT-Rosalind, a research preview life sciences reasoning model specifically built for biology, drug discovery, and translational medicine.
The model series is optimized for scientific workflows, combining tool use with deeper understanding across chemistry, protein engineering, and genomics. It connects scientists to 50+ tools and data sources for research workflows. And OpenAI is working with pharmaceutical companies including Amgen to apply it across discovery workflows.
Drug discovery currently takes 10-15 years from target to approval at a cost of approximately $2.6 billion per drug. The question of whether AI can compress that timeline is one of the more consequential questions in the field. Rosalind represents OpenAI’s most serious attempt yet to have a direct answer.
What This Means If You’re Watching the Space
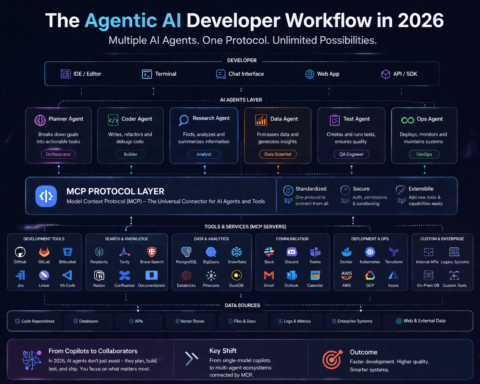
The pattern from this release cycle is clear: the frontier models are converging on capability parity across labs, while the differentiation is increasingly in the applications, integrations, and workflows built on top.
ChatGPT is no longer primarily a chat interface. It’s becoming a workspace — file library, research tool, shopping assistant, interactive learning platform, code execution environment, and soon an agent that can operate your computer in the background while you do other work.
Whether that vision succeeds depends less on the next benchmark improvement and more on whether the execution is smooth enough that people trust it with consequential tasks. The gap between “technically capable” and “actually deployed in production” remains wide, and closing it is the work of 2026.
The benchmark story was always the easy headline. The harder, more important story is whether GPT-5.4 becomes infrastructure — something people depend on daily without thinking about it, the way they depend on email or search. We’re closer to that than most realise.