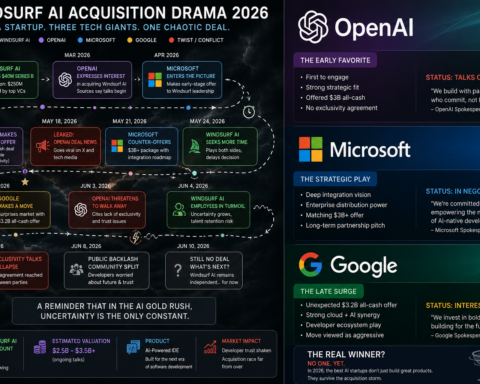
In 2026, 40% of AI startups founded in 2024 are already gone. The seed-to-Series A conversion rate dropped from 24% to 18%. The foundation model providers keep adding native features that obsolete whole startup categories. And yet more AI companies are being started than ever. Here’s what the founders building durable companies in this environment are doing differently.
A European entrepreneur named Violetta Bonenkamp, who advises founders across the continent, wrote something in June 2026 that stuck with me. “Cheap imitation will get punished faster than before,” she wrote. “The market is maturing, and mature markets are less forgiving of shallow products.”
That sentence captures something important about what it means to build an AI startup right now.
There has never been more capital available, more infrastructure accessible, and more public enthusiasm for AI products. There has also never been a faster rate at which AI startups become obsolete — not because the founders failed technically, but because the foundation model providers absorbed the feature they built into their base products. The companies that built AI writing assistants in 2023 were undercut by ChatGPT adding native document editing. The companies that built AI research tools were undercut by Perplexity and then by every major AI product adding web search. The companies that built AI image generation workflows are now competing against DALL-E, Imagen, and Firefly bundled into tools people already pay for.
Building an AI startup in 2026 that’s still standing in 2028 requires understanding this dynamic well enough to build around it, not in spite of it.
The Fundamental Problem With Building “AI Features”
Microsoft’s guidance for founders in 2026 states it plainly: “vision must hold up in production.” The implication is that the vision that gets a startup funded — the impressive demo, the compelling benchmark, the articulate founder explaining what’s possible — is not the same as the vision that gets a startup to Series A. Production means working in real customers’ actual systems, with real customers’ actual data, in real customers’ actual workflows.
The failure mode that destroyed the largest cohort of 2023-2024 AI startups isn’t technical. It’s strategic. They built features. Technically impressive features, sometimes. Features with early adoption and even early revenue. But features nonetheless — things that could be absorbed into existing products without meaningful difficulty once the foundation model providers decided to build them.
A feature is something that does one thing well in isolation. A business is something that creates switching costs, accumulates proprietary advantages, and becomes harder to replace the longer a customer uses it.
The critical test for any AI startup idea in 2026: in 18 months, when GPT-6 or Claude 5 or Gemini 4 has natively absorbed what you’re building, why would customers stay with you?
The answers that work: you have proprietary data that the foundation models don’t have and can’t get. Your product is so deeply integrated into the customer’s existing workflow that replacing it would require disrupting processes that took months to build. You operate in a regulated industry where compliance requirements create barriers to entry that a general-purpose AI can’t cross. You’re building physical systems where the software is inseparable from hardware the customer has already deployed.
The answers that don’t work: our UX is better, our model is fine-tuned, we have a 6-month head start, we have more integrations.
The Data Moat Question (and Why Most Founders Misunderstand It)
“Proprietary data” is the most cited moat in AI startup pitches and the most frequently misunderstood.
The misunderstanding: having data that competitors don’t is a moat. Correct, as far as it goes.
What gets missed: data is only a moat if it creates compounding advantages as you accumulate more of it, and if the cost to replicate it is genuinely prohibitive for well-capitalised competitors.
A startup that has scraped or licensed a dataset that a competitor could replicate in six months with $5 million doesn’t have a proprietary data moat. It has a temporary data advantage that buys time but not durability.
A startup that captures data through the act of providing its service — where every customer interaction generates proprietary training data that makes the product better, which attracts more customers, which generates more data — has a moat. It compounds. Replicating it requires replicating the customer base, not just spending money.
The healthcare AI companies that have processed millions of clinical encounters have data moats. The legal AI companies built on court reporting infrastructure (like Steno, which raised $62 million in 2026) have data moats — every transcript processed trains models on real litigation workflows. The agricultural AI companies with years of crop sensor data have moats. The financial AI companies with proprietary transaction data have moats.
The companies with genuine proprietary data advantages are typically those that either own the data generation mechanism (they’re also the service provider, not just the AI layer on top of someone else’s service) or have built multi-year exclusive relationships with data owners in specific domains.
If your data story is “we have access to the same data as everyone else, but we’ve curated it better,” that’s a temporary advantage. What happens when someone with 10x your budget curates it better with 10x the resources?
The Enterprise Depth Question
The companies getting Series A rounds in 2026 are consistently the ones that demonstrate what investors describe as “enterprise depth” — not just revenue, but the kind of revenue that’s structurally hard to displace.
Enterprise depth means: multi-year contracts with meaningful switching costs, evidence of expanding rather than churning revenue (net revenue retention above 120% is the specific metric investors are looking for), integration into workflows that would be disruptive to change, and a relationship with the customer that spans multiple decision-makers rather than a single champion.
The difference between a startup with $1.2 million ARR on annual contracts and one with $1.2 million ARR on month-to-month subscriptions is not a revenue difference. It’s a survival difference. The month-to-month company is one bad quarter away from losing its entire customer base if a foundation model provider releases a competing feature. The annual contract company has 12 months of runway even in the worst case.
Microsoft’s guidance to founders is direct on this: “questions around scalability, reliability, and enterprise readiness are surfacing much earlier in the startup journey.” Enterprise readiness means: security documentation, SOC 2 compliance, data processing agreements, role-based access controls, audit trails, and the ability to answer procurement team questions about your model training data and privacy practices. These used to be requirements for Series B companies. In 2026, they’re requirements for closing enterprise pilots.
Founders who treat enterprise readiness as something to build later are building something that enterprise buyers can’t purchase. And enterprise buyers — with multi-year contracts and meaningful contract values — are the customers that make the unit economics work.
The Build vs Buy vs Partner Decision
The framework for how to build an AI startup has changed significantly from 2023.
In 2023, the guidance was: use the best available foundation model via API, build your product fast, get to market before someone else does. The underlying assumption was that foundation model API access was the scarce resource and speed was the competitive advantage.
In 2026, foundation model API access is commoditised — you can access GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and Llama 4 at similar price points. Speed to market is still important, but it’s not the primary moat. The guidance has shifted:
Use foundation model APIs for what they’re genuinely good at. Don’t spend 18 months fine-tuning your own model when a well-prompted GPT-5.5 will do 80% of what you need. The infrastructure and inference cost of running your own model is significant; the API economics are increasingly competitive; and frontier model capabilities are improving faster than most startup model development cycles can match.
Build proprietary capabilities in the layers where you have genuine advantages. Your proprietary data, your domain-specific evaluation frameworks, your integration with specific industry software, your fine-tuning on your customers’ specific workflows — these are the layers where building something proprietary creates defensible advantage.
Start with no-code and low-code until you hit a hard constraint. The pragmatic advice from practitioners: default to the fastest possible path to demonstrating value with real customers. No-code automation tools, pre-built integration connectors, API orchestration without custom model development — these get you to real customer feedback in weeks rather than months. The custom build happens when you’ve validated that the no-code approach hits a specific ceiling.
The tactical reality: an AI startup that builds its first product with Zapier, a third-party LLM API, and an existing CRM integration might look “less technical” than one building custom infrastructure from day one. It also reaches paying customers faster, generates real feedback, and makes the specific custom build decision on evidence rather than assumption.
The Governance Problem That Most Early-Stage Founders Skip
Microsoft describes this as “reliability and scalability are becoming core product requirements alongside early customer validation.” The enterprise buyers enforcing this aren’t doing it out of bureaucratic caution. They’re doing it because they’ve deployed AI tools that failed in production, generated wrong outputs, exposed data they shouldn’t have, or created audit trail problems they couldn’t explain to their compliance teams.
The practical governance requirements that come up in every enterprise AI procurement in 2026: Where is customer data stored and who has access? Is the AI trained on customer data? What happens to data after a contract ends? How are AI outputs logged and auditable? What are the escalation paths when the AI produces wrong outputs? How are model updates communicated? What are the data processing agreements?
Founders who build these answers into their product from the beginning close enterprise deals faster than those who scramble to answer them during procurement. It’s not glamorous work. It’s the work that converts pilots into contracts.
The specific technical infrastructure this requires: comprehensive logging of AI inputs and outputs, customer data segregation, model versioning with clear change management, explicit human-in-the-loop workflows for high-stakes decisions, and clear documentation of what the system does and what it doesn’t do.
“Design for auditability” is the June 2026 shorthand for this set of requirements. Buyers want to know what happened, why it happened, and what the system touched. They want to be able to reconstruct any AI decision for compliance, legal, or operational purposes. If your AI operates as a black box that generates outputs without a clear accountability trail, you’re not selling to enterprise buyers. You’re selling to enthusiasts.
The Pricing Question Nobody Answers Honestly
Most AI startup pricing conversations end with “charge for outcomes.” It’s the right long-term answer and the wrong short-term answer for most early-stage companies.
Outcome pricing — charging based on revenue generated, cost reduced, or productivity improved — requires the ability to measure outcomes precisely, which requires data and time that most early-stage companies don’t have. It also exposes the startup to the risk that outcomes are lower than expected in early deployments when the product is still being calibrated.
The practical pricing path: start with workflow volume, seats, or usage — metrics you can measure and defend. As you accumulate evidence of the specific outcomes your product produces for specific customer types, layer in outcome-based elements for the customers where the evidence is strongest.
The companies that are successfully getting enterprise buyers to pay well in 2026 are the ones that can say, specifically, “For a team like yours, we’ve documented an average reduction in X time by Y hours per week, across our seven similar customers.” That specificity — named customers, documented outcomes, comparable situations — is what justifies meaningful contract values. Vague promises of “significant efficiency gains” don’t clear procurement committees.
The unit economics reality: the AI startups that are getting to Series A with strong metrics are running at 60-70% gross margins with clear cost structures for compute, data, and customer success. The ones running at 40% gross margins because their inference costs scale poorly with usage are facing the margin compression problem that makes the path to profitability unclear. Understanding your cost per customer at scale — before you’re at scale — is the financial planning work that separates well-structured businesses from companies that need to raise again every 18 months to survive.
The One Question That Defines Everything
After all the frameworks — data moats, enterprise depth, governance, pricing — there’s a simpler way to evaluate whether an AI startup idea has durability.
Ask: in 2028, when the foundation model capabilities are significantly better than they are today and the infrastructure costs are significantly lower, would a customer who’s been using your product for two years choose to keep using it rather than switching to whatever the baseline alternatives are at that point?
If the answer depends on “we’ll be better by then too,” you’re betting on a race you might not win.
If the answer is “yes, because two years of using our product has produced proprietary data, deep integrations, and documented ROI that would be expensive and disruptive to replicate,” you’re building a business.
The market in 2026 is actively punishing the first kind of company and rewarding the second. That signal is clearer now than it’s been at any point in the AI startup era. The founders who read it correctly and build accordingly are the ones who will be standing in 2028, when the next wave of capital arrives and asks: which companies actually survived?