Anthropic released Opus 4.7 on April 16, 2026, with real benchmark gains — 87.6% on SWE-bench Verified, a 3x jump in image resolution, and agentic tasks that actually complete without hand-holding. But there’s a tokenizer change that nobody is talking loudly enough about. Here’s the full honest review.
Let me start with what triggered this release, because it gives context to why the improvements matter.
In the weeks before Opus 4.7 launched, there was growing noise in developer communities that Opus 4.6 had quietly degraded. An AMD senior director wrote on GitHub that Claude had “regressed to the point it cannot be trusted to perform complex engineering.” Reddit threads documented agentic tasks that used to complete cleanly now stalling halfway through, requiring constant nudging. Anthropic denied deliberate changes and said it would investigate.
Whether or not there was actual degradation or just shifting expectations, Opus 4.7 is partly a reputational reset — and it needed to be a convincing one. The benchmark numbers make a solid case. The question is whether those numbers translate to the tasks you actually do, and whether the hidden cost of the new tokenizer matters for how you use it.
Let’s go through it clearly.
The Coding Improvements: Real, Not Marketing
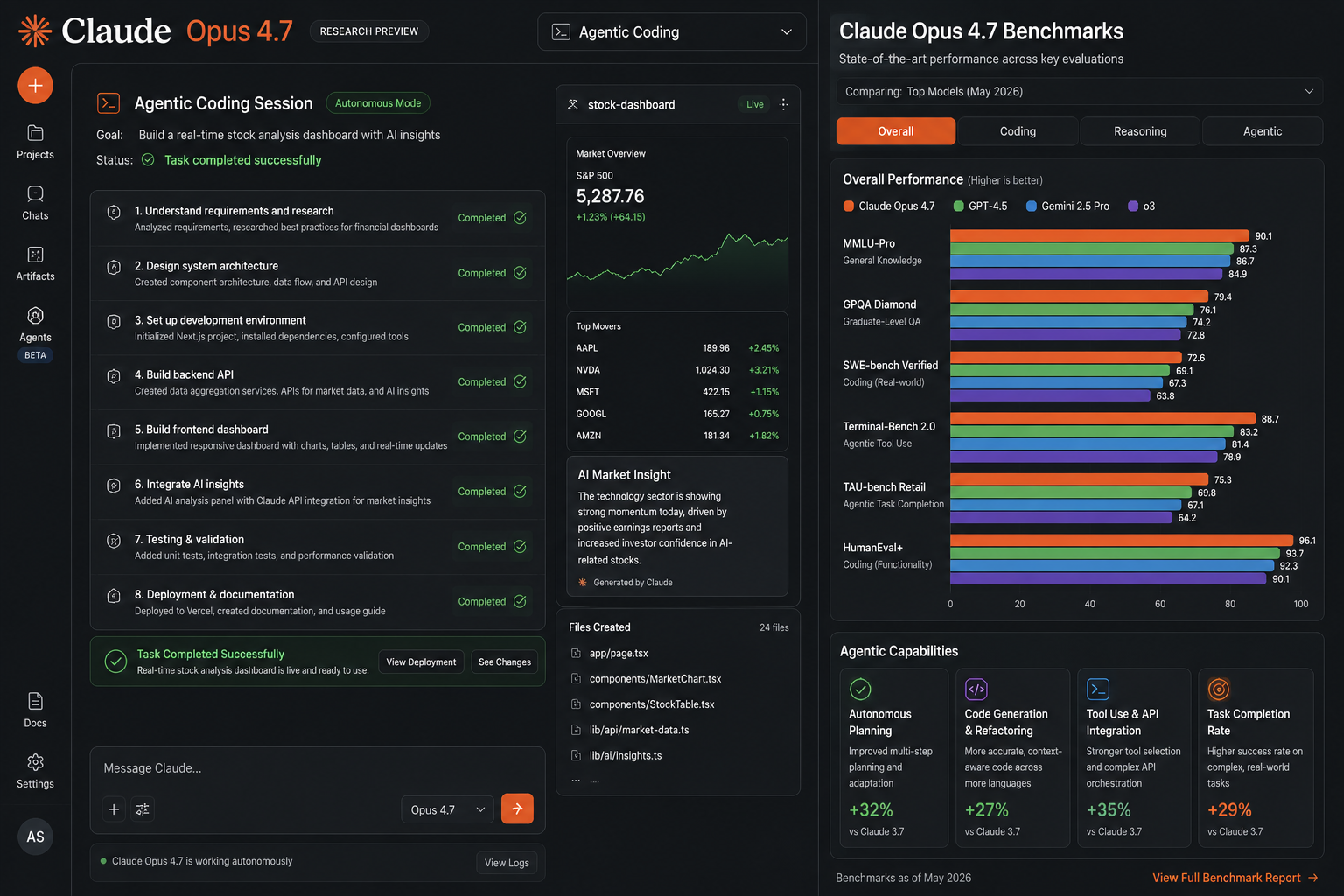
SWE-bench Verified — the 500-issue, human-validated benchmark of real GitHub problems — went from 80.8% on Opus 4.6 to 87.6% on Opus 4.7. That’s a 6.8-point gain in a single version. For context, GPT-5.4 sits at approximately 74.9% and GPT-5.5 at 58.6% on SWE-bench Pro. Opus 4.7 reaches 64.3% on that harder benchmark.
More relevant than the benchmark numbers is what developers who’ve tested it early are saying.
Factory Droids reported a 10-15% lift in task success with fewer tool errors and more reliable follow-through on validation steps. Vercel called it “phenomenal on one-shot coding tasks, more correct and complete than Opus 4.6, and noticeably more honest about its own limits.” They noted a behaviour they hadn’t seen in earlier Claude models: the model now does proofs on systems code before starting work — essentially checking its approach before committing.
The most useful real-world demonstration in Anthropic’s announcement: Opus 4.7 autonomously built a complete Rust text-to-speech engine from scratch — neural model, SIMD kernels, browser demo — then fed its own output through a speech recogniser to verify it matched the Python reference. That’s self-verification, which is exactly what’s been missing from AI coding agents that complete tasks confidently but incorrectly.
On CursorBench — the benchmark that measures AI coding performance specifically inside the Cursor IDE — Opus 4.7 jumped from 58% to 70%. If you’re using Claude inside Cursor, that’s a meaningful improvement you’ll notice in daily use.
The one genuine regression in coding: Terminal-Bench 2.0, which tests complex command-line workflows. Opus 4.7 scores 69.4%; GPT-5.5 scores 82.7%. If your primary use case is terminal-based agentic coding, GPT-5.5 in Codex is the better choice right now. That’s worth knowing before you switch.
The Vision Upgrade: A Bigger Deal Than It Sounds
Opus 4.7 increased maximum image resolution from 1.15 megapixels to 3.75 megapixels — roughly 3.3x the previous limit.
If you haven’t been doing vision-heavy work with Claude, this might sound irrelevant. But there’s a class of workflows where this change is significant: computer use agents, screenshot analysis, document understanding, diagram interpretation, and code review via visual interfaces.
The previous 1.15MP limit meant that detailed screenshots — say, a complex UI screenshot for computer use — came through at insufficient resolution for precise analysis. At 3.75MP, the model’s visual accuracy changes qualitatively. Anthropic reports 98.5% accuracy on the standard vision benchmark with the new resolution. The previous limit wasn’t bad; this is substantially better.
The coordinate system also improved. Previously, the model’s coordinates needed scaling before they mapped to actual pixels. Now they’re 1:1 with actual pixels, which simplifies computer use agent development significantly — no more scale-factor math in your prompts.
If you’ve been routing vision tasks to GPT-5.4 because Claude’s image handling was unreliable, it’s worth revisiting. This specific gap has closed.
The Agentic Reliability Improvement: The Most Practical Gain
This is the improvement that matters most for anyone building AI agents or running autonomous coding tasks.
Opus 4.6 had a documented problem with multi-step task completion: it would start, make progress, and then subtly abandon subtasks or generalise an instruction in ways that weren’t requested. Opus 4.7 addresses this directly. According to Anthropic’s own documentation: “The model will not silently generalise an instruction from one item to another, and will not infer requests you didn’t make.”
The practical result: Opus 4.7 is roughly 60% less likely to drop subtasks in long agentic sequences compared to 4.6. That’s not a complete fix — edge cases still exist — but it’s the difference between an agent that needs close supervision and one you can hand a complex task and reasonably expect to see through.
Task budgets, a new feature, give the model a rough estimate of how many tokens to target for a full agentic loop — including thinking, tool calls, and output. The model sees a running countdown and prioritises work accordingly, finishing tasks gracefully as the budget depletes. For developers running expensive agent sessions, this prevents the silent token burn that previously made long agentic tasks economically unpredictable.
The new xhigh effort level (at 100K tokens) also deserves attention. At xhigh, Opus 4.7 scores 71% on complex tasks — already ahead of Opus 4.6’s maximum performance. Think of it as putting the model into its highest-concentration mode for work that genuinely requires it.
The Hidden Cost: The Tokenizer Change
This is the thing most reviews mention briefly and then move past. It deserves more attention.
Opus 4.7 uses a new tokenizer. Anthropic’s own documentation states it can use “roughly 1x to 1.35x as many tokens when processing text compared to previous models.” In real-world testing, the increase is typically 12-18% for English text. For non-Latin scripts (Japanese, Arabic, etc.), the new tokenizer is actually more efficient — but most of the users reading this are working primarily in English.
The sticker price is unchanged: $5 per million input tokens, $25 per million output tokens. But if the same prompt and completion now use 15% more tokens on average, your effective cost per task has increased by 15% even though the listed rate is identical.
For individual Claude Pro subscribers ($20/month), this doesn’t matter — you’re paying a flat rate. For anyone using the API at scale — developers running agentic workflows, companies processing high volumes of documents — this is a real budget variable that needs to be accounted for before migrating.
The practical advice: before migrating production API workloads to Opus 4.7, replay a sample of real production prompts and measure actual token consumption. Don’t rely on the sticker price alone. The model is better; it may also cost more than the rate card suggests.
Additionally: if you have existing code that uses temperature, top_p, or top_k settings, they’re gone. Setting any of these to a non-default value now returns a 400 API error. thinking.budget_tokens is also removed. These are breaking changes that require code updates before migrating.
Who Should Upgrade — And When
Upgrade immediately if: You’re using Opus 4.6 for coding-heavy work. The SWE-bench gains are real, the agentic reliability is improved, and it’s included in your existing Claude Pro or Max subscription with no price change.
Upgrade immediately if: You do vision-heavy workflows — screenshots, diagrams, computer use, document analysis. The resolution jump is the biggest single improvement in this area Anthropic has shipped.
Test carefully before migrating if: You use the API at scale and pay per token. The tokenizer overhead means effective costs per task may be higher than the rate card implies. Validate on real production traffic before committing.
Stay where you are if: Your primary use case is terminal-based agentic work where GPT-5.5 leads on Terminal-Bench 2.0. Or if you need creative writing or web research quality — BrowseComp showed a regression in 4.7 vs 4.6.
For Claude Code users specifically: The /claude-api migrate Skill in Claude Code handles most of the API migration changes automatically. Run it first, then do a manual pass for any custom prompt tricks that relied on temperature settings.
The Honest Verdict
Claude Opus 4.7 is a genuine upgrade for the use cases where Claude was already strong — coding, agentic task completion, and now vision — and doesn’t surrender meaningful ground elsewhere, except on Terminal-Bench and BrowseComp.
The reputational reset it was designed to accomplish is real. The benchmark gains are real. The improved instruction-following and agentic reliability address the specific complaints that preceded the release.
The tokenizer cost is real too, and it’s the detail you need to understand before deploying at scale.
The bigger picture context: Claude Mythos Preview, which Anthropic is keeping restricted to its Project Glasswing security partners, scores 93.9% on SWE-bench Verified — roughly 6 points above Opus 4.7. There’s a more capable model in the building that isn’t publicly available yet. Opus 4.7 is excellent by any normal measure. It’s also the second-best model Anthropic has right now, which is worth knowing when planning what comes next.
Rating: 4.6/5 — the strongest coding AI available to the general public in May 2026, with a caveat about the tokenizer overhead that matters at scale.