xAI cut Grok’s API price by 60% and added native video input and downloadable file output in the same update. At $1.25/M input tokens, it’s the cheapest frontier-class AI available. But the best version is locked behind $300/month, and Grok’s political opinionatedness is genuinely a product concern, not just a Twitter talking point. Here’s what 30 days of real use looks like.
I want to start with something that should disqualify me as a Grok reviewer and actually makes me more credible: I didn’t want to like it.
The Elon Musk association has made Grok politically charged in ways that are unusual for an AI tool. The X integration makes it feel inseparable from that platform’s particular atmosphere. The “anti-politically-correct AI” positioning has always struck me as more marketing than engineering. I came into this review expecting a product that was interesting on specs and compromised in practice.
What I found is more interesting than that. Grok 4.3 is genuinely capable in specific areas, genuinely frustrating in others, and priced in a way that makes the API version one of the most attractive deals in AI right now — while making the premium version hard to justify against ChatGPT Pro and Claude Max.
Let me walk through it honestly.
What Actually Changed in Grok 4.3
Released in late April 2026, Grok 4.3 is the most significant update xAI has shipped since Grok 4.20 launched in March. Three changes are substantive:
Price cut. Grok 4.3 now runs at $1.25 per million input tokens and $2.50 per million output tokens — an input reduction of roughly 40% and an output cut of approximately 60% compared to Grok 4.20. For context: OpenAI charges $30 per million output tokens for GPT-5.5 Pro. Anthropic charges $25 for Claude Opus 4.6. Grok 4.3 at $2.50 is a genuinely different cost category. For high-volume API use where you’re not specifically hitting tasks where GPT-5.5 or Opus 4.7 are significantly stronger, Grok 4.3 is the obvious budget choice.
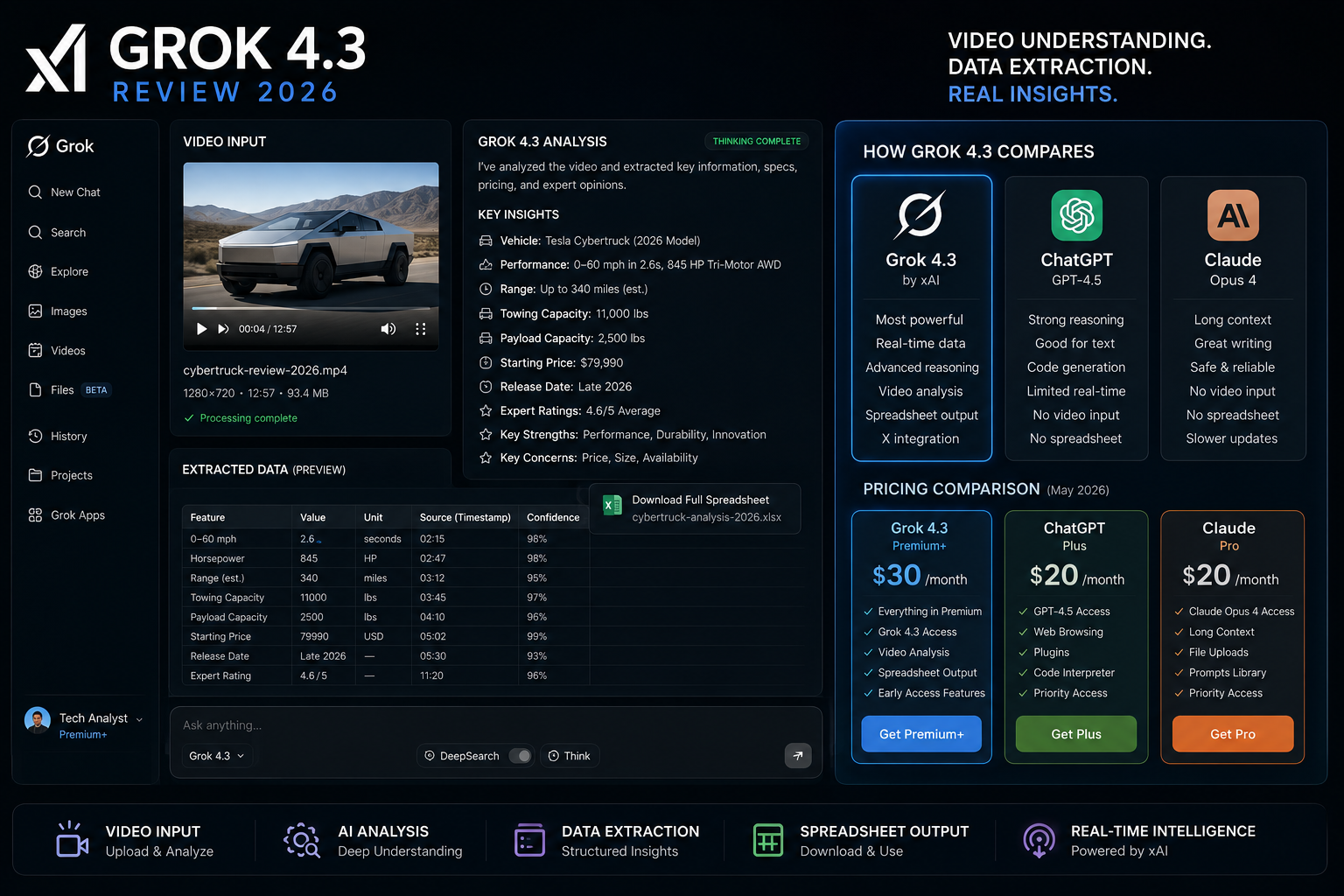
Native video input. This is the feature addition that matters most for multimedia workflows. Grok can now process video files directly — not through transcription, but through native video understanding. Combined with the 1 million token context window (which handles roughly an hour of video content), this opens Grok to use cases it couldn’t touch before: video content analysis, meeting recording summarisation, video-based research tasks. GPT-5.5 doesn’t do native video input. Gemini Ultra does, but charges more for it.
Real file output. Grok 4.3 can now generate downloadable PDFs, fully formatted spreadsheets, and PowerPoint decks directly from conversation. Early testers report formatted outputs you could actually hand to someone — not the “here’s the content, you go format it” approach most chatbots produce. This sounds small; in practice, for anyone who regularly needs to take AI-generated analysis and package it into a deliverable, it eliminates a meaningful manual step.
The Real-Time Data Advantage — Grok’s Actual Moat
Of all the capability differences between Grok and its competitors, the one that’s hardest to replicate is the X (Twitter) data integration. Grok has access to real-time information from X’s feed — posts, trending topics, emerging news — that no other AI provider has without third-party web search.
This matters specifically in contexts where X is a primary information source: financial markets (where breaking news moves prices before traditional media reports), sports (live commentary and reactions), geopolitics (where X often carries on-the-ground reporting hours before mainstream outlets), and AI itself (where X hosts more AI researcher discussion than any other platform).
If your work requires staying on top of breaking developments and X is part of how you track them, Grok’s native X integration is a genuine competitive advantage that ChatGPT’s web search and Perplexity’s crawling can’t fully replicate. The freshness of information is qualitatively different.
For everything else — academic research, technical analysis, document processing — Grok’s information access is similar to any other tool with web browsing capability.
The Capability Honest Assessment
Where Grok 4.3 genuinely performs:
Reasoning. On benchmark data, Grok 4 uses a four-agent collaborative architecture that produces strong reasoning performance. In practice — running Grok through a set of analysis tasks, strategic frameworks, and complex decision scenarios — the reasoning quality is competitive with GPT-5.4 and Claude Opus 4.6 on most tasks. Not uniformly better. Competitive.
Real-time tasks. Any task where current information matters, Grok’s X integration and web access combination produces strong results. Competitive intelligence, news synthesis, market trend analysis, tracking developing situations — Grok is frequently the best starting point.
High-volume workflows. At $1.25/M input tokens, running Grok for tasks that require many API calls — content classification, data enrichment, document summarisation at scale — is dramatically more economical than frontier competitors. If you have a workflow that works adequately with Grok’s capability level, the cost argument is compelling.
Where Grok 4.3 doesn’t perform as well:
Complex coding. On SWE-bench, GPT-5.5 (at 58.6% on Pro) and Claude Opus 4.7 (at 64.3% on Pro) outperform Grok’s published scores. For serious multi-file coding work, the gap is real and noticeable in practice. Grok handles straightforward coding tasks well; it’s at the frontier on complex, agentic coding tasks.
Long-form writing and nuance. Claude’s prose quality remains noticeably higher on complex writing tasks. Grok’s outputs sometimes feel faster and more decisive — which is an advantage for quick-turnaround tasks and a disadvantage when nuance matters.
The opinionatedness problem. This is the thing that reviews either ignore (because they’re pro-Grok) or exaggerate (because they’re anti-Musk), so let me try to be specific. Grok’s training reflects Elon Musk’s worldview more directly than other models reflect their founders’ worldviews. On politically charged topics — certain economic policies, particular figures in tech or media, some social issues — Grok produces responses that feel tilted in ways that other frontier models don’t. This isn’t universal. For most professional tasks, it doesn’t appear. For tasks that touch areas where Musk has strong public positions, it’s detectable.
Whether this matters to you depends on what you’re using AI for. If you’re doing market research, coding, analysis, and content work — probably doesn’t matter. If you’re doing research on topics where Musk’s perspectives overlap with the subject matter, it’s worth being aware of and cross-checking.
The Pricing Situation: Honest About the Complexity
This is where I need to flag something that the initial coverage of Grok 4.3 understated.
The $1.25/M input, $2.50/M output pricing is API pricing. If you want Grok 4.3 through a chat interface, you currently need the SuperGrok Heavy tier at $300/month. Standard SuperGrok ($30/month) has Grok 4.3 visible in the model selector but the rollout to that tier is gradual and expected mid-to-late May 2026.
At $300/month, xAI is going head-to-head with ChatGPT Pro ($200/month) and Claude Max ($200/month). That’s a $100 premium for a model that’s competitive but not decisively superior to what you get at $200/month from OpenAI or Anthropic.
The value proposition is genuinely different depending on which tier you’re on. At the API level, Grok 4.3 is one of the most interesting value plays in AI right now. At the SuperGrok Heavy chat tier, you’re paying more than ChatGPT Pro for a different product, not a better one.
For API developers: The price cut is real and significant. If your workflow doesn’t require the specific areas where GPT-5.5 or Opus 4.7 lead, Grok 4.3 at these prices deserves serious evaluation.
For chat users: Wait for the standard SuperGrok ($30/month) rollout in late May before deciding. Paying $300/month for Grok Heavy when ChatGPT Pro or Claude Max are available at $200/month requires a specific, compelling reason — probably the X data integration or the video input.
For teams evaluating a second model: Grok makes particular sense as a “second model” to keep on hand for video review, real-time information tasks, and high-volume agentic work where price sensitivity matters. That’s how the Fello AI multi-model setup (bundling Grok, Claude, ChatGPT, Gemini) is being used by many power users who want access to all four without multiple subscriptions.
The Honest Verdict
Grok 4.3 is a better product than its reputation suggests and a more politically influenced product than its boosters admit. Both of those things are simultaneously true.
The price cut is the most important development in this release. API developers who’ve been ignoring Grok because of the Musk association should revisit the economics with fresh eyes. At $2.50/M output tokens versus GPT-5.5 Pro’s $180/M, the gap is enormous. For the right use cases — high volume, real-time information, video analysis — the business case is now clear.
The $300/month chat tier is harder to justify. Wait for the standard SuperGrok rollout.
The opinionatedness concern is real but bounded. Know when it matters for your specific tasks, and cross-reference where it does.
Rating: 3.9/5 overall — but 4.4/5 specifically for API use cases where price and real-time data matter, and 3.4/5 for premium chat users where ChatGPT Pro and Claude Max offer more at lower cost.